
Jakub Michalski
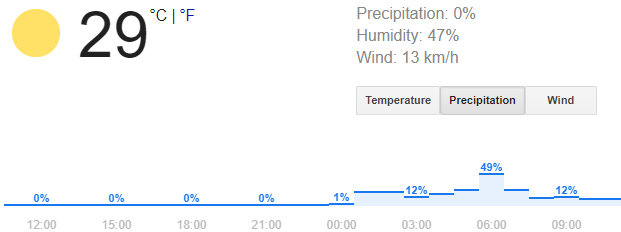
The real world is incredibly complicated (especially in 2021), so modelling everything perfectly is just not possible. But, if we want to predict the future – for example to forecast the weather – we need to create models. So, we simplify our world, omit some less important factors and create probability models. These models estimate how likely it is for different event to happen. For example, if you look up the weather in Google it will not tell you “it is going to rain tomorrow”. However, it will tell you that there is a 49% chance that it will be raining tomorrow morning:
Gutenberg-Richter Law
Of course the weather is not the only natural phenomena we might want to model. In the middle of the 20th century two scientists, Gutenberg and Richter, spotted that the number of earthquakes of different magnitudes seemed to follow a pattern. They described the pattern using the following law:
𝑁 = 10−𝑏𝑀
Where M is the magnitude of an earthquake, N is the probability of an earthquake of magnitude M occurring, and b is a parameter that depends on the region and time. For regions seismically active it is close to 1.
If we plot this for 𝑏=1 we have:

As you can see, the frequency of earthquakes of higher magnitude drops quite sharply to almost zero for anything above 2 on the Richter scale. And as it turns out, even though this model is incredibly simple, it describes the probability very well – real world data for earthquakes follows the same exponentially decreasing pattern. However, the model does not give us any insight into the chance of an earthquake happening in a particular area, and as such it cannot be used to forecast future quakes.
Heads or Tails
Yet, not all of our models are so accurate. Take for example another model which you probably remember from school maths lessons – flipping a coin. This model tells us that we have a 50/50 chance of getting tails or heads. But, strictly speaking, this is not true! There is a nonzero chance of a coin landing on an edge, as we can see in the below video clip from a football match between Colombia and Paraguay:
So, why are we using this simplified model? The answer is because it is “good enough”. The chance of a coin landing on an edge is ridiculously small, so in the real world it barely ever happens. Moreover, it is hard to estimate the chance of this happening, and is much easier to describe a model where there are only 2 outcomes of equal probability. This hints at a general concept found in all levels of mathematical modelling – the real world is messy. You simply can’t include everything that can possibly happen. What if the coin falls into the sewer, or if a crow flying overhead catches the coin mid-air? Are these events likely? Not at all. Can they happen? Absolutely. Does it make sense to include them in our model? Not really. Models that do not include everything can still help us to understand the real world, as long as we are aware of their limitations.
Birthday paradox
Here’s a question for you – how many people need to be in a group for it to be more likely than not that two of them have the same birthday? You may intuitively think that it must be quite a large number, but as it turns out, the group only needs to have 23 people for a greater thnn 50% chance that two of them share a birthday. This quite surprising result is named “The Birthday Paradox”. If this is the first time you’ve come across this problem, do check out this article from another TRM intern, Kai Laddiman, to see how it all works.
Now, given the tone of the article so far, it may not surprise you to learn that this paradox is not entirely true. When creating a model of the situation, we assume that the same number of babies are born every day of the year. This is not the case. When we look at data from the Office for National Statistics we can see that even though this assumption is true for most days, there are days with substantial differences. For example, more babies are born in September and October than in the other 10 months of the year, and less babies are born on 25th and 26th December and 1st January (maybe they don’t want to interrupt their parents’ festivities?).
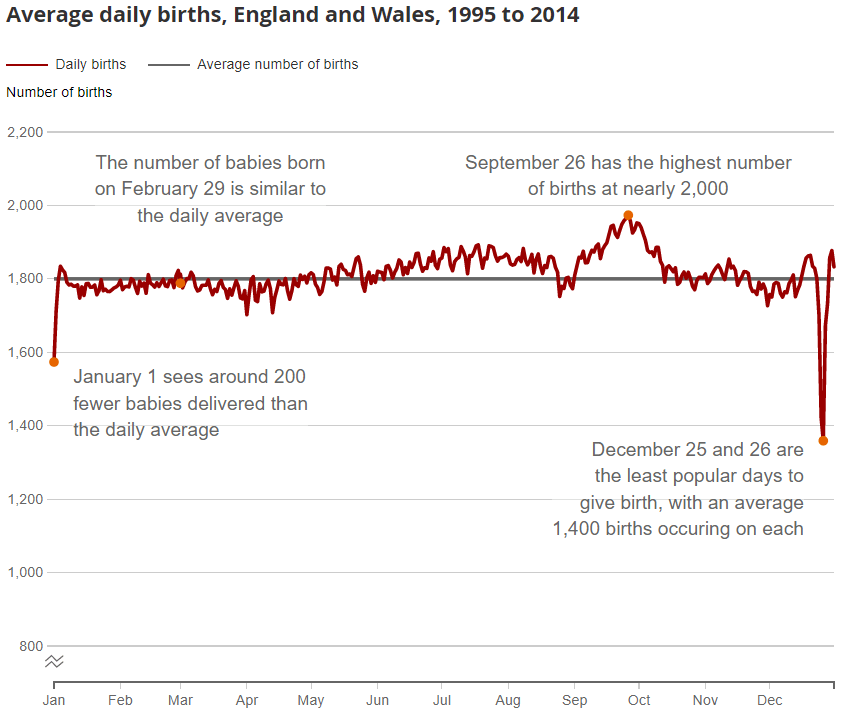
Moreover, in some groups birthdays may be even more skewed. There is reasonably strong evidence that top athletes tend to be born near to the beginning of the year. Children born in the first couple of months are bigger and stronger than their peers, simply because they are older, and so coaches select them more often for their teams – you can read more about the phenomena here.
So, does it mean that we should completely disregard the results from the Birthday Paradox model? Well, just like the model for flipping a coin, it still gives us useful insight – even if the numbers are a little out. The model helps us to understand probability and why is it not uncommon to hear of multiple people in football teams sharing birthdays (a typical squad will contain 20-25 players). In fact, if we were to include the uneven birth rates, it would turn out that we need even fewer than 23 people for the probability of a shared birthday to greater than 50%.
At this point in the article, you will no doubt be wondering why is it that we so often use models that are simple, but slightly wrong? And the answer is for the most obvious reason – they are simple. It is easier to create and use them, so we can save time. In addition, quite often it is just not possible to create a perfect model, because the real world is far too messy and complicated (again I’m looking at you 2021). Simple models are still useful so long as we remember their limitations. When transferring the mathematical results back into the real world, it is imperative that they are applied to situations where the assumptions of the model hold true.
An infamous example of the misinterpretation of mathematical models comes from the Black-Scholes equation and the financial crash of 2008. The Black-Scholes equation is widely used in financial modelling to estimate the value of stock options. As with most models, the equation is built on a few major assumptions, with one of the most important being that big movements of the market will only happen very, very infrequently. But, as it turned out in 2008, this was a gross underestimation. Moreover, the popularity of the model meant that everybody started to use the same calculations, and as such received the same results, further destabilising the market. Ultimately, this was not a problem with the model itself – this was a problem with people using the model without taking into consideration all of its’ limitations. You can read more about the Black-Scholes equation and the role it played in the 2008 financial crash here.
So, in conclusion, mathematical models are a very important and valuable tool that help us to understand the world around us – from predicting the weather, to planning joint birthday parties – but, things can quickly go wrong if we forget about the underlying assumptions on which they are based. And if the assumptions themselves aren’t particularly clear, then even stranger things can happen as we saw previously with the Bertrand Paradox...

[…] you are interested in probability and paradoxes, check out my two other articles – about probability models and how can they mislead us, and the Bertrand […]
LikeLike