
Wilf Offord
When you hear the word ‘quantum’, be it on the news, in popular media etc, there’s a good chance your mind just translates it to ‘magic’. It’s an unfortunate side-effect of the kind of jargon thrown around in certain sci-fi films and books, where any time something baffling or unexplainable happens it’s often chalked up to some vague ‘quantum effect’. But this is strange: quantum mechanics was discovered almost 100 years ago, and by now almost all scientists who are concerned with it accept it as a basic fact about the world, not some zany far-fetched speculation. It’s been confirmed time and time again in experiments, and is used every day in household technology, from USB drives to fluorescent lights. And yet, it is still treated by many as some esoteric, almost mystical theory only accessible to a small minority of cutting-edge scientists. Nowhere is this more apparent than in quantum computing, which has in recent years become the buzzword of choice for the technology of the future. But what actually is a quantum computer?
The most fundamental difference between a quantum computer and a normal (classical) one lies right down at the level of bits. All classical computers work by moving information from one place to another in the form of bits – if you’re not familiar with the idea, a bit is the smallest unit of information that computers handle. They have just two states, 0 and 1, and you can think of this as whether a certain switch or electric current is ‘on’ or ‘off’. All information stored in a computer is represented in this way; for instance, the letter ‘A’ encoded as a sequence of 0’s and 1’s might look something like this: 01000001.
So, what’s different in quantum computers? Instead of using bits, quantum computers rely on what are known as quantum bits, or qubits. There isn’t one specific object that we call a qubit, rather this refers to any system that can be in two states (like the two states of a classical bit). Above we’ve seen the example where the two states are ‘on’ or ‘off’, but we can have other states such as a particle spinning* either clockwise or anticlockwise, or jumping between two energy levels. More abstractly, the two states of a qubit are often represented like this:
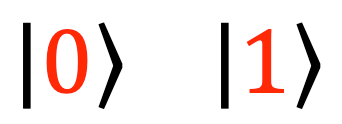
Importantly, however, this system has to be on a small enough scale that we minimise interaction with the outside world if we want to start to see quantum theory in action. You see, the thing about quantum mechanics is that while we can only observe a certain set of possible outcomes (e.g. rotating either clockwise or anticlockwise), before we actually make a measurement there is no definite fact about which state the system is in: rather, it can be thought of as in some ‘mix’ of the two. Often, this mix is represented visually as a point on a globe called the Bloch Sphere:
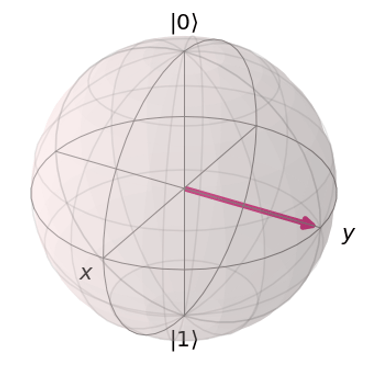
You may have heard about this in the famous thought experiment involving Schrödinger’s cat. An unfortunate cat is in a box with some toxic gas that may be randomly released at any moment. Only when we open the box will we be able to see that the cat is either alive or dead, but before we make the observation (i.e. open the box) it is somehow in a mix of the two: ‘alive and dead at the same time’.
This effect is known as superposition, when a system is in a combination of two or more states at once. In the maths of quantum mechanics, this precisely corresponds to ‘adding’ multiples of the states. For instance, if the system were in the state:
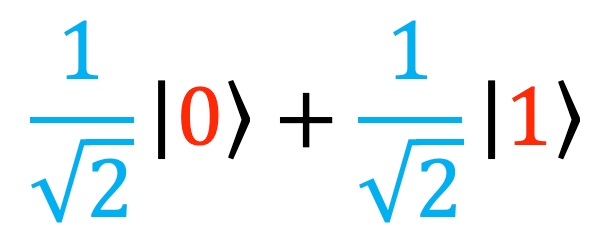
This would tell us that if we were to measure the system, we would have a 50% chance of measuring the state ‘0’, and a 50% chance of measuring ‘1’. (The square roots are there because in order to determine the probability of measuring each state, the maths tells us to square the number in front of it.) Similarly, if we had the state:
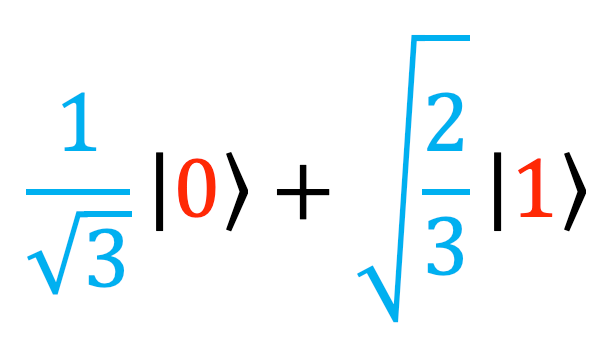
We would have a 1/3 chance of seeing ‘0’ and a 2/3 chance of seeing ‘1’.
So, what does this mean for us when we try to build computers out of qubits? Well, note that now, a single qubit can be in infinitely many configurations depending on the numbers we multiply each state by, rather than a classical bit which only has two. In a sense, before we measure it, a qubit is storing a great deal of ‘hidden information’ and we can hope to use this additional information capacity to run computations much faster than classical computers. To make this a little more concrete, suppose we want to do some calculation for each input, 0 or 1 (we can later scale this up to more inputs by adding more qubits). By first putting the qubit in the state above (with the coefficients 1/sqrt(2)), then applying something called a quantum logic gate (which will be some physical process occurring to the qubit in the computer), we can apply a function to the ‘0’ part and the ‘1’ part at the same time, to get:
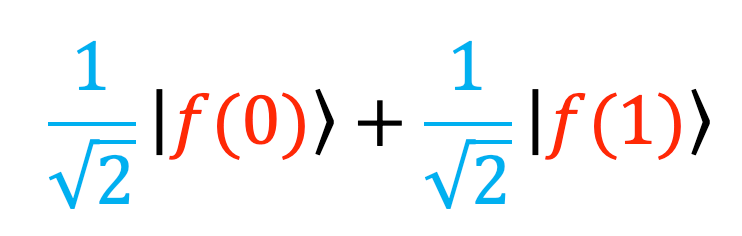
Where we are writing ‘f(0)’ to mean the output of the calculation when we plug in 0, and similarly for 1. (The actual function or procedure this represents isn’t important here, just that we can do it and get the result as above.)
While there are more intricacies involved in how to apply such a logic gate, and how to work out which output corresponds to which input**, this is the fundamental idea behind quantum parallelism; a classical computer would have to evaluate the function twice, once for each input, but a quantum computer gets away with just one evaluation! We get the results for both 0 and 1 at the same time from only one operation. When we scale up to more qubits, the benefits become even more pronounced.
So, what’s the catch? Remember how I said earlier that whilst before you measure it, a qubit can be in a mix of two states, but when you measure it, it must be in one or the other? Well, it turns out this is a big problem for our hopes of simultaneously making many calculations at once. You see, when we make a measurement, whichever output we obtain becomes the new state of that qubit – it has ‘collapsed’ onto either 0 or 1. So whilst we have succeeded in creating a qubit state that has all the information we want, after we make a measurement, the extra ‘hidden information’ is instantly destroyed!
But all is not lost – despite this problem, quantum algorithms do exist that can make use of properties of qubits like quantum parallelism, so that they are much more efficient than their classical counterparts. For instance, while we can’t get both outputs from a single observation, we can in fact use further quantum gates to get other information – for example the sum of the outputs. Whilst theoretical obstructions like this mean quantum programmers have to find clever work-arounds, there are known quantum algorithms that would drastically affect the modern world. One famous example is Shor’s Algorithm which can efficiently factor large integers (see here for why that’s important!)
The incentives are definitely there to build functional universal quantum computers, which is why they’re talked about so much. It wouldn’t just represent a slightly faster new supercomputer with more efficient components, but a whole new paradigm for computation, with many exciting new doors open to us. And rapid progress is being made: in 2020 the University of Science and Technology of China (USTC)’s Jiuzhang system made a calculation that would have taken a classical supercomputer 2.5 billion years to complete – using up to 76 qubits in tandem! We know quantum computers have the potential to be vastly faster than classical ones at a specialised set of tasks, and there is progress to be made not just on an engineering level, but also on a theoretical one in discovering useful algorithms like Shor’s. So, for the time being it looks like quantum computers are here to stay – and who knows, one day you may even have one in your home.
* particles don’t really ‘rotate’, but there are in fact many real properties we can measure that can have one of two values: real quantum computers often use either photons or trapped charged particles at two different energy levels.
** really we have to use at least two qubits which are entangled (something for another article).

[…] which has a specific technical meaning in the world of quantum computing. If you haven’t already, check out my first article on quantum computing here, but I will do a quick recap of the important bits (no pun […]
LikeLike
You write: “The incentives are definitely there to build functional universal quantum computers.” Well, you must be an optimist or a romantic or a superposition of the two. My opinion is that at the end of this ceintury only a few very big companies will possess a quantum computer. By then global use is still out of the question! I’m afraid that it will only make the differences in the world bigger than they already are,
LikeLike