
Gavin Jared Bala
We recap from last time the formal definition of a group by general properties:
A group is a set of objects (called elements), with an operation on them (which we will denote by * in analogy to multiplication), such that:
- There is an identity element, which we call 1 in analogy to multiplication, satisfying 1*x = x*1 = x for all x in the group.
- There are inverses: for every x in the group, there is some other element, which we’ll call x-1, such that x*x-1 = x-1*x = 1.
- The operation is associative: for every x, y and z in the group, we have x*(y*z) = (x*y)*z.
- The operation is closed: if x and y are in the group, then x*y is also in the group.
We’ve already seen, twice over, a small group with six elements: the symmetries of an equilateral triangle (known as D6). And we’ve also seen a large group with infinitely many elements: the integers under addition. The number of elements of a group is called its order: so D6 is a group of order six. (The subscripts usually show the order, but not always, as evidenced by another name for this group being S3.)
But let’s not run before we can walk. What are the smallest groups that we can think of?
Well, a group certainly must have at least one element. After all, property 1 above stated pretty clearly that there is an identity element. But notice that nothing says that there is anything else.
Indeed, the group with exactly one identity element and nothing else is the smallest group! It is a group of order one, and it’s obviously unique up to isomorphism (see part I for an explanation of this term). It’s often called C1. But one might equally think of it as the symmetry group on one or zero elements, and call it S1 or even S0. (The one way to rearrange one or zero elements is to do nothing!)
It might seem a bit silly, but it’s actually important. For example, this is the group of symmetries of an irregular object that we would commonly say has no symmetry. For it does have one symmetry – the symmetry of leaving everything alone, which is the identity.
Later, as we learn to build up large groups from small groups, in about the same way we can build large numbers from small ones by multiplying up their factors, we’ll see that this smallest group takes on an analogous role to 1 in the integers. Indeed, the analogy is so strong that this group is often just called 1 – but since we’re already pushing the analogy by calling any identity element 1, let’s not do that right now.
What about order two? One element was guaranteed to be the identity, so that’s settled. What’s the other one? We don’t know much about it, so let’s call it a.
Here we note something. A group is defined as a set with an operation – which means that we’ve defined a group so long as we know how all elements multiply against each other.
We know that 1*a = a*1 = 1, because that’s how an identity is supposed to work. We also know that 1*1 = 1 for the same reason. So the only question is: what’s a*a?
It cannot be a, because a must have an inverse, and we can cancel by using associativity:
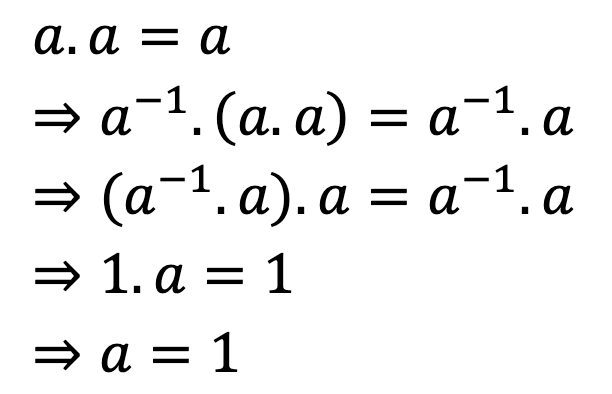
That means that we did not have a second element after all: contradiction.
So, the only possible choice is to have a*a = 1, giving a multiplication of the following variety:
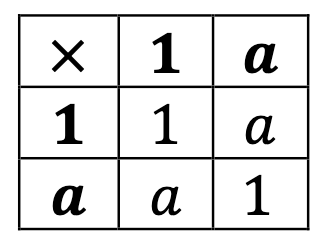
This is a group called C2, and it is the only group of order two. It can be thought of as the symmetry group of something like a human, with only bilateral symmetry: the only symmetries are the identity and a reflection. It is also the symmetric group S2 on two elements: all that we can do is swap them.
Such a multiplication table, defining a group, is called a Cayley table.
Constructing Cayley tables is actually a useful way to figure out what the really small groups must look like. To see why let’s see what the properties of a group tell us about a Cayley table:
- The fact that there is an identity means that there must be an element 1 whose row just leaves anything alone, like the one times table.
- Because there are inverses, the element 1 must appear somewhere in every row.
- Even further, every element can only appear once in every row! The reason is simple. If a*b = x, and yet also a*c = x, then as above we could cancel the a’s with their inverses and get b = c = a-1*x. That means that b and c were not really different.
- Similarly, every element can only appear once in every column.
- However, since the number of elements equals the number of rows, that means that no element can be absent – and the same for columns. Therefore, every element appears exactly once in every row and every column – which is called the Latin square property.
Incidentally, this shows us Cayley’s theorem. It states that every group is contained in a symmetric group.
This is because if a group has n elements, we can arrange them in a “queueing list”. Multiplying by an element a gives us the multiplication table row of a, and therefore rearranges the elements in another queueing list. So every element can be thought of as a reordering, though of course not every reordering will necessarily correspond to an element.
This incidentally also notes that as a worst case scenario, the group will be contained in the symmetric group permuting its number of elements. In some cases, though, this is obviously overkill. We could include D6 into S6 as it has six elements, but it’s a lot easier to include it in S3 – because, as we’ve seen, it is exactly S3.
Notice however that we don’t get any easy way to check associativity, which will turn out to be a problem later.
Armed with this, let’s proceed on to groups of order three. One of the elements will be the identity 1; we’ll call the others a and b. Let’s immediately fill in what we know of the Cayley table: that identities do nothing multiplicatively.
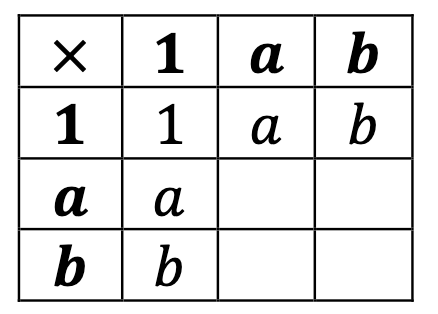
Filling in the rest of the square is a bit like solving a Sudoku, given the Latin square property!
Could a*a be 1? The second row has to contain one copy of every element, so that would force a*b to be b. But we can’t have that, because then the third column duplicates b!
Could a*a be a? That wouldn’t work either, since that row and column already has an a in it!
Therefore, a*a = b, and the Latin square property gives us a*b = b*a = 1:
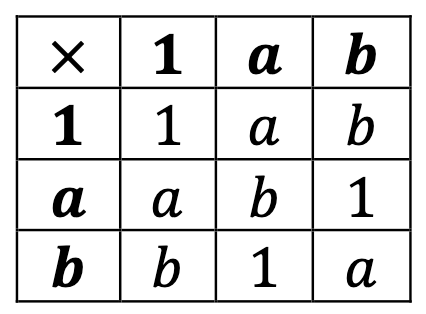
The table thus neatly completes in one possible way: b*b must be a.
This group is called C3, and it’s the only group of order three.
But how do we know it is a group? We haven’t checked associativity.
We can avoid having to check every single case for associativity by noting that this is actually part of the group of equilateral triangle symmetries. If we keep 1 as the identity, and identify a as rotating 120° clockwise and b as rotating 120° anticlockwise, we’ll see that everything checks out: these elements form a group by themselves.
There’s also an inherent symmetry in this group, because we could just as well have proclaimed that a was rotating 120° anticlockwise and b was rotating 120° clockwise. In other words, the group table remains the same if you swap the labels of a and b – so the group itself has a symmetry group! Since this and the identity are the only such symmetries, we can deduce that this symmetry group of C3 is none other than C2. The way this C2 acts on our original C3 is to swap a and b.
A symmetry of a group is called an automorphism, as it is an isomorphism between a group and itself. So we say that the automorphism group of C3 is C2, or for short: Aut(C3) = C2.
The smaller groups don’t have any symmetries but the identity, since only the identity can play its own role, and there simply aren’t enough other elements to do any swapping. So we have Aut(C1) = Aut(C2) = C1.
Now it’s also possible to see where these groups are coming from. Let’s switch to a more addition-inspired notation, in which the identity is more easily labelled 0. Then the groups C1, C2, and C3 are naturally expressed as addition tables in the following ways:
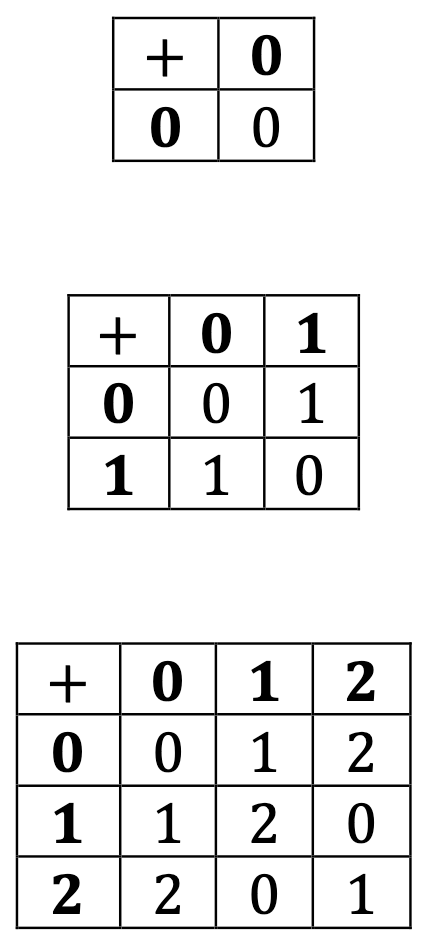
We can now see what’s going on. These are the “additions” of an odometer that has only the numbers up to a certain point; to go further, it returns to 0 and starts counting again.
Or we can think of them as cycling n people arranged in a circle: the person at “the head of the circle” changes, but they never change their relative order.
Similarly, this is the symmetry group of a regular polygon when mirrors are forbidden: only rotation is allowed.
For all these reasons, these groups are called cyclic groups. There exists a unique cyclic group of any order n: it’s called, as one would expect by now, Cn. And indeed, we can now confess that the C stood for cyclic all along!
Could we go one step further? Let’s try order four. We first get a blank table:
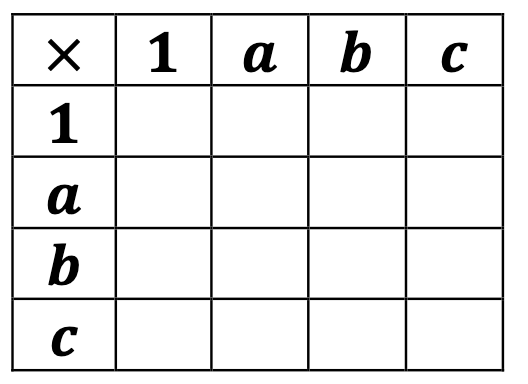
and fill it up with what we know about the identity:
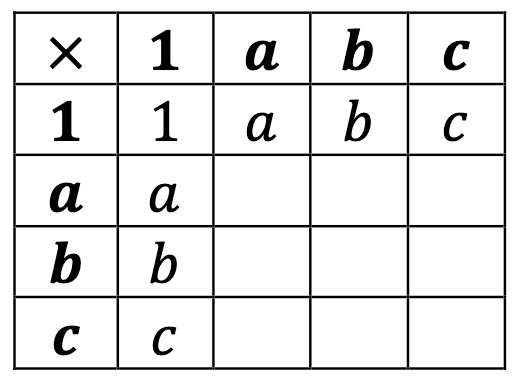
Now, what could a*a be?
It’s certainly not a, but it could be anything else, so far as we know for now.
Let’s proceed case by case.
If a*a = 1, then we know that a*b cannot be 1 or a, because we can’t repeat anything in the row. But it also can’t be b*b because we can’t repeat anything in the column, so we have a*b = c. Thus a*c = b to let everybody appear in the second row.
By exactly the same logic, b*a = c and c*a = b, so we can fill in some more of our table:
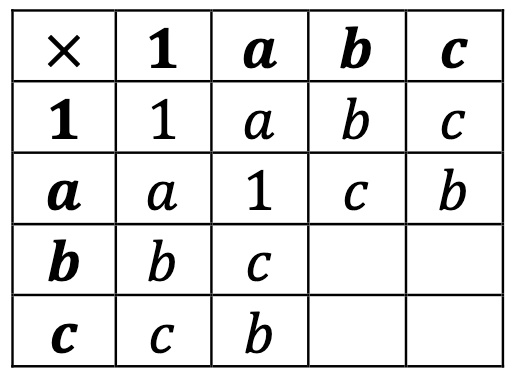
One option for the remainder is to declare that b*b = 1, in which case the rest of the table fills up by the Latin-square property:
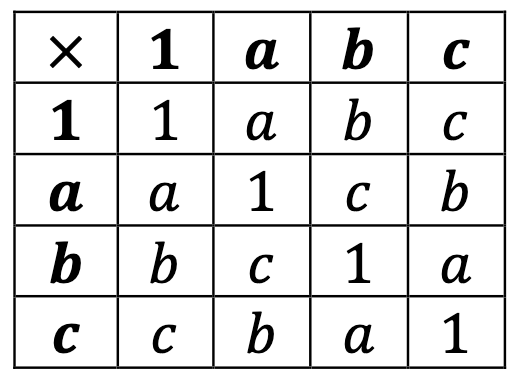
This group, in which every element is its own inverse, is called V4: the Klein four-group. It is the symmetry group of a rectangle: think of a as reflection in the horizontal, b as reflection in the vertical, and c as rotating by 180°.
The other choice is to take b*b = a, which means that b*c = c*b = 1 and thus c*c = a:
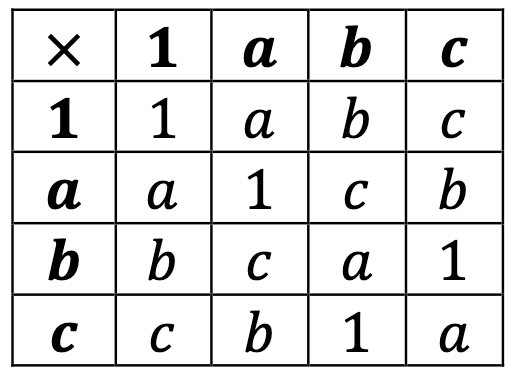
To better identify this group, let’s reorder the elements:
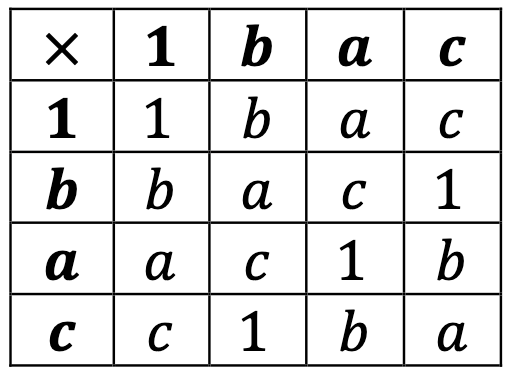
And let’s relabel 1, a, b, and c as 0, 1, 2, and 3, changing the operation to addition:
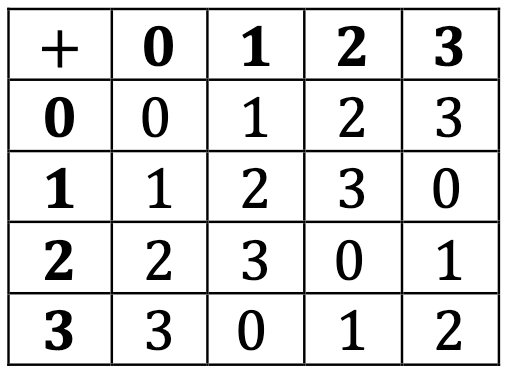
Aha! Now everything is clear: this is a slightly disguised version of the cyclic group C4.
For completeness, we will try to figure out what the automorphism groups of these two groups are.
Let’s think of C4 as the rotational symmetry group of a square. As for the triangle, we could associate 1 to either rotation by a right angle clockwise, or a right angle anticlockwise. But that’s all we could do (swap 1 and 3), as clearly nothing else acts like the identity, or the half-turn (which when applied twice, unlike the other nontrivial symmetries, becomes the identity). Therefore, Aut(C4) = C2, this time swapping 1 and 3.
The situation for V4 is more interesting. The three non-identity elements of this group all square to give the identity, and multiplying any two of them gives the third one. But there is no other way to distinguish them, so any rearrangement of them preserves the group structure and is therefore an automorphism. Therefore, Aut(V4) = D6 – so a symmetry group might have more symmetries than the object it was describing!
Now, what we should do is proceed to the next case, taking a*a = b, and then taking a*a = c. We will not do this here: you might like to try it for yourself. However, you’ll find that you only get more disguised and relabelled versions of the cyclic group C4.
We are already seeing this method wearing out, though it has served as well thus far. The problem is that once we get to order four, we start having too many cases. Even worse, the casework isn’t very effective; many cases simply lead to the same thing over and over in different disguises.
Even worse, we must check associativity: we don’t get it for free from just the Cayley table guaranteeing the other properties! Consider for example the following Cayley table, with just five elements (the first order we have not covered):
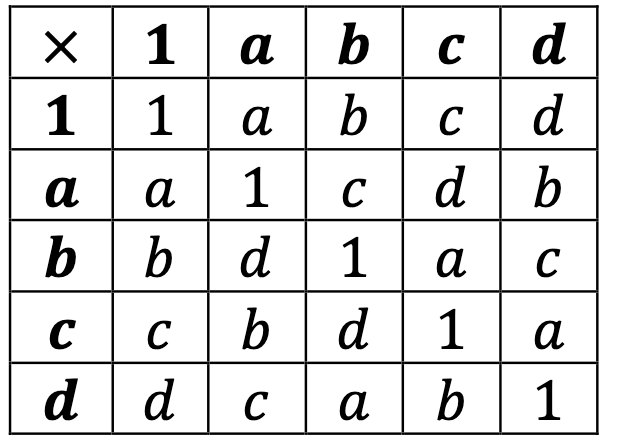
This is a valid Cayley table; it contains an identity, and every element has an inverse. But the multiplication it defines is not associative. As a concrete example:
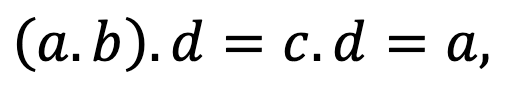
but
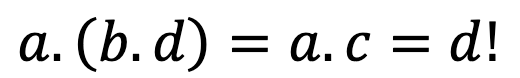
Such a structure, which satisfies all properties of a group but associativity, is called a loop.
We have avoided needing to check associativity entirely by noticing isomorphisms between the groups we created and symmetry groups; but at some point, this is not going to work out. Not all groups can be realised as the symmetry group of an object in ordinary space! And if it turns out that we don’t have a group, like above, then obviously we’d never find out this way unless we checked cases.
In order to continue our search for groups more effectively, we’re going to need to step back and think about some general properties. Which is exactly what we’ll be dong in part III – see you there!

[…] It certainly looks like groups are even more omnipresent than we had thought. So we had better get some more understanding of them through small examples… see you for part II! […]
LikeLike
[…] one element has to be cyclic, so we could not generate V4 = {1, a, b, c} by one element (see previous article for a discussion of where V4 comes from). But if we examine the tables in the previous […]
LikeLike
[…] in part II we went up to order four, and in part III we went up to order eight, it seems natural to end off by […]
LikeLike