
Megan Bell
Picture the scene. You’re a homicide detective on one of those ‘CSI-type’ shows. You’ve found a DNA sample left at the crime scene, but no other evidence to try and find your suspect. You decide to run the DNA sample through a database of known criminals, and you get a match. Surely you’ve found your killer?
According to Bayes’ Theorem, probably not. We’ve seen in the first article that there are often other factors at work – eg. Steve the librarian – and the same is true here…
Suppose this database contains 100,000 samples of DNA from convicted criminals, and the investigators know from previous cases that there is a 1 in 10,000 chance that a random match can just be found by chance, and so won’t correspond to the guilty person. A prosecutor might say “the chance of a random match is only 1 in 10,000, so the person found by DNA match must be guilty because this is such a small probability”, but they would in fact be very wrong.

Because the database is so large, 1 in 10,000 corresponds to 10 additional potential matches (shown in red ). Therefore, there might in fact be 11 matches from the database, and only one of these corresponds to the guilty person (green). Therefore, there is only a 1 in 11 chance that the match found is the guilty person! Furthermore, if the real perpetrator hasn’t committed a crime before they might not even be in the database at all – DNA evidence on its own is not enough.
By comparison, let’s say there are 10 suspects who already have a motive and the means to commit the crime. If their DNA is compared to the crime scene sample, and there is a match, it’s much more likely to mean they are guilty, because there was already a 1 in 10 chance of them being guilty before the new evidence was presented.
Unfortunately, this doesn’t just happen in movies and TV shows. The prosecutor’s fallacy may sound like the title of a new fantasy novel, but it’s a very real and very dangerous fault in statistical reasoning, usually made by a lawyer representing either the victim or the accused. The statistics used are correct, but it’s the misinterpretation of these numbers that can lead to a serious miscarriage of justice.
Before we look at a real case, let’s go through an example. Imagine there is a witness present to give evidence against the person accused. The witness claims the person who committed the crime had red hair, and the defendant matches this description. Let’s assume this takes place in Scotland, where about 6 in every 100 people are red-headed, and the witness can correctly identify when a person is red-headed or not 95 out of 100 times.
First, we’ll consider this graphically. Suppose there are 1000 people who could be a suspect, which means 60 of them will have red hair. The witness will identify 57 of these people as having red hair correctly, as they are 95% accurate. Of the 940 people who do not have red hair, the witness will identify 47 of these people as having red hair incorrectly, as they are wrong 5% of the time. Therefore, the witness will identify 104 people in total in every 1000 as having red hair. Of these, only 57 actually have red hair, so there is a 57/104 = 0.548 or a 55% chance the person who committed the crime actually had red hair.

Let’s check this again using Bayes’ Theorem. From the first article, Bayes’ Theorem states

Here, A is the person who committed the crime having red hair, and B is the witness stating they have red hair, so this becomes

The probability of the witness identifying the suspect as having red hair, given they do have red hair is 0.95 = P(B|A), as this is the accuracy of the witness. The probability the suspect has red hair is 0.06 = P(A), as there are only 6 in every 100 people who have red hair.
The probability of the witness saying the suspect has red hair is calculated as the sum of the probability that the witness is right (the person has red hair and the witness correctly says they do) and the probability of the witness being wrong (the person doesn’t have red hair but the witness says they do). This is very similar to the disease testing case from the second article, summing the probability of a true positive and a false positive.
There are 6 redheads in every 100 people, and the witness will correctly identify these people 95 out of 100 times, so the witness correctly identifies a redhead with a probability of 0.95 x 0.06 = 0.057, or 5.7 in every 100 cases. There are 94 non-redheads in every 100 people, and the witness will wrongly identify these people as having red hair in 5 out of every 100 cases. The probability of this happening is therefore 0.05 x 0.94 = 0.047, or 4.7 in every 100 cases. Plugging these numbers in:
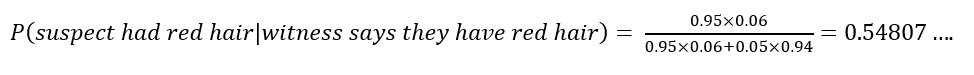
This is very similar to the farmer/librarian problem seen in the first article. The judge might assume that since the witness is accurate 95% of the time, there is a 95% chance that the person who committed the crime had red hair, which could lead to an innocent person being found guilty because they were the most likely suspect with red hair.
Of course, if the defendant is a suspect for reasons other than just being a redhead, the probability they are guilty is higher than this 55%. So it’s very important to consider all the evidence presented, which is why if there is only one form of evidence such as a witness’ testimony, it can be very difficult to prove innocence or guilt.
This was of course just a made-up example to illustrate the concept, but as mentioned earlier there are many real-life court cases where a misuse of Bayes’ Theorem has had devastating consequences.
In 1998 in the UK, Sally Clark was convicted of killing her first-born child at 11 weeks old, and then her second child at 8 weeks old. An expert witness, Sir Roy Meadow, who was a professor and consultant paediatrician, testified against Sally Clark. He stated that the probability of two children from the same family both dying from SIDS (Sudden Infant Death Syndrome) was approximately 1 in 73 million, and so the chances of her being completely innocent were very small. This was the first – but not the biggest – mistake.
By using Bayes’ Theorem and historical data, it can be seen that if one child has died from SIDS in the family, the chance of another child dying is now greater than before, as there might be a genetic susceptibility to it. This is similar to the idea we mentioned in the first article about insurance premiums and lightning strikes for example.
Correctly calculated, the chance of two siblings both dying from SIDS remains very low, but on its own, this probability is still meaningless. What wasn’t considered at all, is that the chance of a mother killing both her children as infants is also very very small, as is one of them dying from SIDS and the other being murdered. The probability of both children dying from SIDS must be measured against the probability of all other outcomes.
Later in 2002, a professor of mathematics, Ray Hill, estimated that the probability of a double homicide was between 4.5 to 9 times less likely than both infants dying from SIDS, later publishing a paper on this topic. Sally Clark was released in 2003 following an appeal in a higher court, but she had already served 3 years in prison.
People like Sally Clark can’t get those years back. Before her trial, she was a successful lawyer, but during her imprisonment, she developed a serious alcohol dependency and died in 2007 from alcohol poisoning. Judges and Lawyers need to properly understand Bayes’ Theorem to prevent these mistakes from being made again, and such a simple-looking formula really can be the difference between life and death.
In this series of articles, we’ve explored how Bayes’ Theorem can guide disease testing, legal cases, filter out junk email and even crack war-time ciphers. This is just the tip of the iceberg, but hopefully you can appreciate just how vital this equation is for just about everything around us. And next time you watch a murder mystery drama, you can decide for yourself if they’ve really found the killer.
Article 1: Ghosts, Spam Emails and Bayes’ Theorem
Article 2: Bayes’ Theorem and Disease Testing

[…] So far in this series we’ve been introduced to Bayes’ Theorem and seen how it can help governments to stop outbreaks of viruses like COVID-19, and screen for deadly diseases like cancer; but it also has a vital role to play in our courtrooms. When judges and lawyers don’t apply Bayes’ Theorem properly, there can be life-changing consequences, which we will discuss in the final article of this series. […]
LikeLike
[…] As we shall see in the rest of this series of articles, this seemingly simple equation could be the difference between life in prison and walking free, and can help to explain why accurate tests for diseases are so vital to stop […]
LikeLike